Unlocking the Power of Embeddings: A Deep Dive into Models and Their Applications
Embeddings are revolutionizing how we process and understand data in AI. This article explores various embedding models, their specific uses for different text types, and the underlying reasons that make these associations crucial for effective data representation.
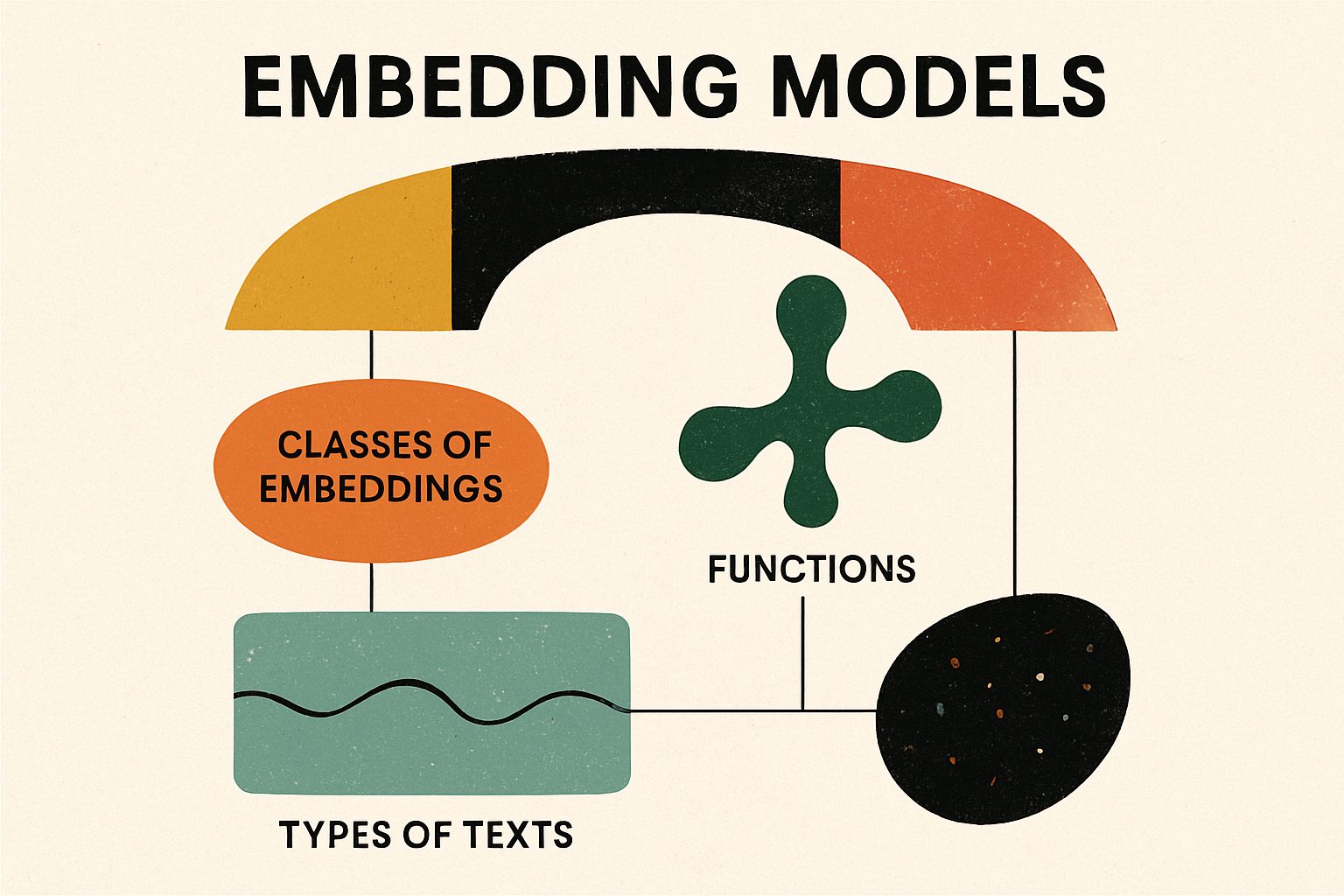
This comprehensive analysis explores Compare the various embedding models, explaining their functions and the different classes of embeddings that exist. Specifically, identify which embeddings are suitable for different types of texts, illustrating this relationship and clarifying the reasons behind these associations., based on extensive research and multiple data sources.
Below is a comprehensive research overview that explains the various embedding models, their functions, and the classes of embeddings used across different modalities. In particular, it describes which embeddings best suit different types of texts, along with the rationale behind these associations.
Thesis:
Embedding models are foundational to modern AI, transforming high-dimensional data into compact, continuous vector representations. Each class of embedding—whether for words, sentences, images, or graphs—has been fine-tuned for specific data structures. By understanding their functions, training techniques, and context-specific advantages, practitioners can select the appropriate embedding model that best suits the text type or data modality they are processing.
“Embeddings represent high-dimensional data as vectors in a lower-dimensional space, making it easier for computers to process unstructured data such as text, images, and audio.”
– Embedding Models: A Comprehensive Guide for Beginners to Experts
What Are Embeddings?
- Definition:
Embeddings are numerical vector representations that capture semantic meaning and structural relationships in data. - Purpose:
These representations enable efficient computation and similarity measurements crucial for tasks such as classification, clustering, retrieval, and recommendation.
The main classes of embeddings can be categorized as follows:
- Word Embeddings:
- Examples: Word2Vec, GloVe, FastText
- Function: Represent individual words as dense vectors that capture semantic relationships.
- Suitability: Best for tasks like synonym detection or sentiment analysis where the focus is on the meaning of individual terms.
-
Strength: Captures local lexical co-occurrences.
-
Sentence & Paragraph Embeddings:
- Examples: Universal Sentence Encoder, Sentence-BERT (SBERT)
- Function: Capture the overall meaning of sentences or paragraphs by aggregating word embeddings.
- Suitability: Ideal for semantic textual similarity, question answering, and document classification tasks.
-
Strength: Maintains contextual nuances over larger text units.
-
Character Embeddings:
- Examples: Custom-trained models using frameworks like Keras for character-level tokenization
- Function: Models text at the level of individual characters which helps when dealing with misspellings or rare vocabulary.
- Suitability: Suitable for processing languages with complex morphology or for handling out-of-vocabulary tokens.
-
Strength: Captures nuanced syntactic and morphological features.
-
Multimodal Embeddings:
- Examples: CLIP (for image and text), Audio embeddings with models like Wav2Vec
- Function: Map content from different modalities into a shared space to enable cross-modal retrieval and classification.
- Suitability: Perfect for tasks where text is combined with images or audio, such as caption generation or multimedia search.
-
Strength: Aligns heterogeneous data sources.
-
Graph Embeddings:
- Examples: Node2Vec, GraphSAGE
–
Below is a comprehensive research analysis on adaptive and dynamic techniques, providing a detailed exploration of adaptive methods, their application in software development and machine learning, and an evaluation of their advantages and challenges.
Thesis & Position
Adaptive techniques offer a flexible, continuous, and user-centered approach to both software development and machine learning. In dynamic, rapidly evolving markets, these techniques empower teams and systems to respond in real time to new information, user requirements, and environmental changes. By embracing iterative cycles, feedback loops, and continuous learning, adaptive methods enhance innovation and efficiency across various technology domains.
Evidence & Factual Information
Adaptive Software Development (ASD)
Adaptive software development (ASD) is recognized as a leading approach in agile methodologies. It replaces rigid, linear models (such as the waterfall paradigm) with a fluid cycle comprising speculation, collaboration, and learning stages. Key characteristics include:
- High Flexibility: Teams adjust plans based on continuous user feedback and emergent project conditions.
- Iterative Cycles: Short development cycles allow for regular re-assessment, minimizing risks and ensuring that projects evolve in line with stakeholder needs.
- Change Tolerance: ASD adapts to evolving requirements and unexpected challenges see Wikipedia.
“Adaptive techniques replace the traditional waterfall with cycles of planning, building, and review, ensuring that the final product is closely aligned with current user needs.”
– ThinkPalm Technologies
Adaptive Learning in Machine Learning
In the realm of machine learning, adaptive learning refers to methods that modify algorithms in response to new data or environmental changes. Common adaptive techniques include:
- Supervised, Unsupervised, and Reinforcement Learning: Each approach relies on learning from data—whether labeled, unlabeled, or via interaction—to adjust strategies dynamically.
- Techniques such as Decision Trees, Neural Networks, and Clustering Algorithms: These methods learn and evolve, fine-tuning performance over time source.
Adaptive methods in machine learning create systems that can handle evolving datasets, anomalous events, and changing patterns, thereby enhancing applications ranging from image recognition to natural language processing.
Critical Analysis & Comparative Perspectives
Comparison of Adaptive Techniques
Below is a comparative table summarizing adaptive software development versus traditional agile methods:
| Aspect | Adaptive Software Development (ASD) | Traditional Agile (e.g., SCRUM) |
|---|---|---|
| Flexibility | Highly adaptive and explorative | Relatively structured sprints |
| Iteration Cycles | Short, dynamic cycles (speculate, collaborate, learn) | Fixed sprint cycles |
| User Involvement | Continuous, high-level engagement | Regular but structured involvement |
| Scope Tolerance | High tolerance for scope changes | Limited scope creep |
| Risk Management | Risk-driven adaptations | Mitigates risks within sprint cycles |
Both approaches share a focus on iterative development but ASD is particularly suited to environments
Below is a detailed research analysis comparing various embedding models, their functions, and the classes of embeddings. The discussion also clarifies which embeddings are best suited for different types of text data and explains the reasoning behind these associations.
Thesis & Position
Embedding models are fundamental in transforming unstructured text into low-dimensional numerical vectors that capture semantic meaning. These embeddings lie at the core of numerous NLP tasks—from text classification and semantic search to recommendation systems. In this analysis, we explain the functions of embedding models, classify them by the granularity of text they process (e.g., word, sentence, character), and assess which types are most suitable for different text types.
Classes of Embeddings and Their Functions
Embedding models can be broadly classified into several groups. Each class is tailored to capture various aspects of language and provide different benefits:
- Word Embeddings
Examples: Word2Vec, GloVe, FastText
These models represent individual words as dense vectors. They excel at capturing local and global semantic similarities, such as the classic relationship “king” − “man” + “woman” ≈ “queen” (Medium guide).
Suitable For: - Short texts or isolated words
-
Applications requiring quick lookup of semantic similarity (e.g., synonym detection)
-
Sentence and Paragraph Embeddings
Examples: Universal Sentence Encoder, Sentence-BERT
These embeddings capture the overall meaning of sentences or paragraphs by pooling word-level information, thereby maintaining context and nuance (LearnOpenCV).
Suitable For: - Longer texts where context matters (e.g., summarization, sentiment analysis)
-
Applications requiring holistic understanding (e.g., question answering systems)
-
Character Embeddings
These models represent text at the character level and are especially useful when dealing with out-of-vocabulary words or languages with rich morphology. They can capture subword relationships and are implemented via architectures that process sequences at a finer granularity (ML with Ramin).
Suitable For: - Noisy data or unconventional terms (e.g., social media text)
-
Languages with complex morphology or scripts
-
Domain-Specific and Multimodal Embeddings
Examples: MedEmbed for medical texts; CLIP for text-image pairs
These models are fine-tuned or trained specifically on data from particular domains or across modalities, thereby improving performance when transferred into specialized tasks ([Adnan Masood](https://medium.com/@adnanmasood/the-state-of-embedding-technologies
Vyftec – Embedding Models Analysis
At Vyftec, we excel in AI and machine learning, offering deep insights into various embedding models and their applications. Experience Swiss-quality solutions tailored to your text analysis needs.
📧 damian@vyftec.com | 💬 WhatsApp